AI Cost Firewall vs. VCAL Server: What’s the Difference and How to Choose

Many customers ask us about the difference between AI Cost Firewall and VCAL Server, and how to choose between them.
The two products are not the same. They differ in purpose, integration style, and the level of control they give to application teams. But they are built around the same core idea: helping AI applications avoid repeated LLM work, improve visibility into AI usage, and reduce unnecessary token spend.
This article is a simplified guide to the purpose of both products, the differences between them, and the situations where each product fits best.
Intro
In many AI applications, users repeatedly ask questions that are not completely identical, but are close enough for the system to reuse a previous answer. A support chatbot may receive the same question in different wording. An internal assistant may repeatedly summarize similar documents. A RAG system may answer the same operational question many times for different users.
This is where caching and control layers become useful.
The VCAL project includes two related but different products for this problem: AI Cost Firewall and VCAL Server.
They both help reduce repeated LLM work and unnecessary token spend, but they are designed for different integration styles and different use cases.
The simple difference
The simplest way to explain the difference is this:
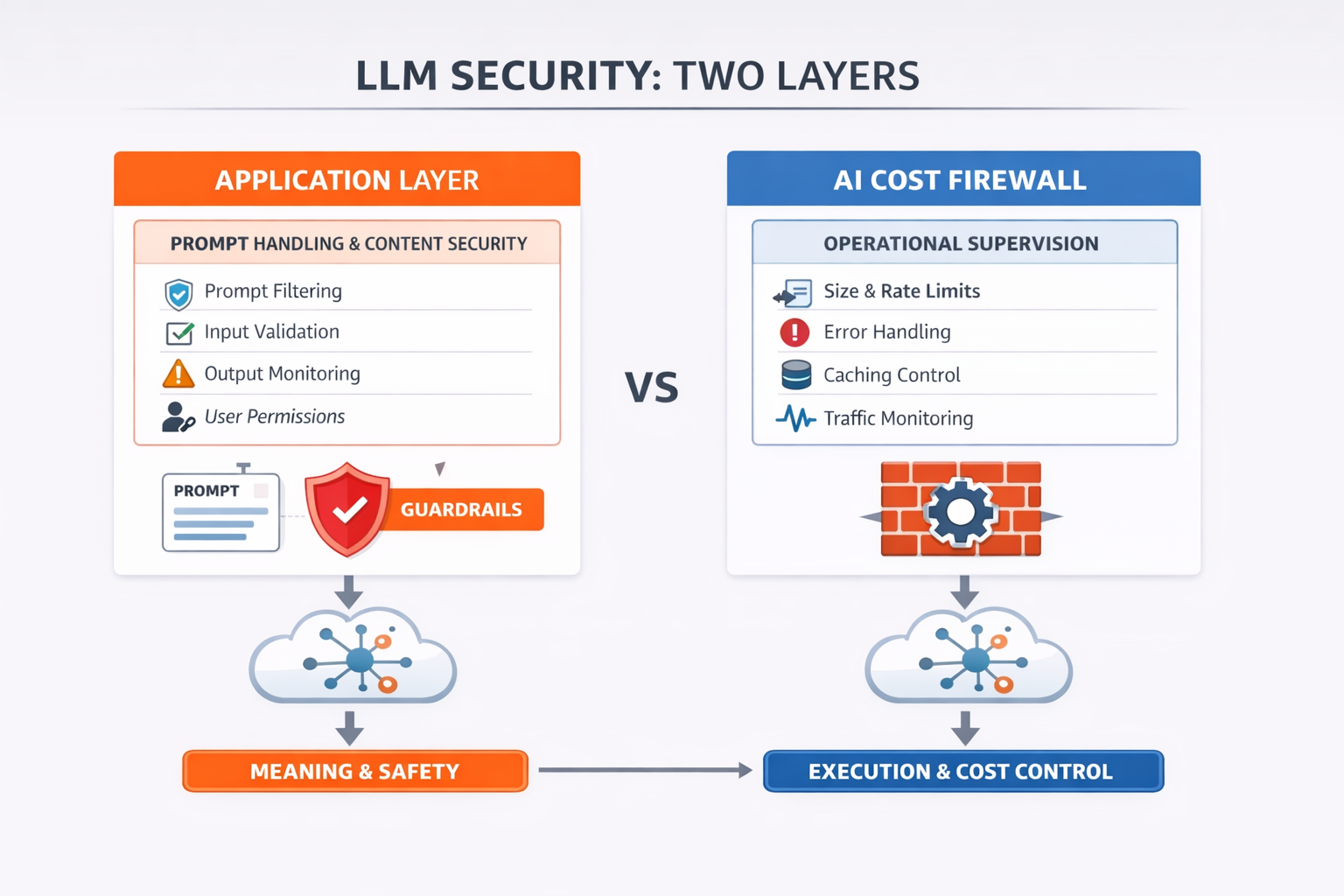
AI Cost Firewall is a gateway.
AI Cost Firewall sits between an application and an LLM provider. It is designed for OpenAI-compatible APIs, so an existing application can often start using it with minimal changes.
VCAL Server is a semantic cache service.
VCAL Server is different. It does not try to behave like OpenAI, Anthropic, Gemini, or any other LLM provider. Instead, it exposes its own REST API for semantic cache operations. Applications integrate with it directly when teams want more control over how cache lookup, reuse, storage, and decision logic work.
Both approaches are useful, but they solve the problem at different levels.
What AI Cost Firewall does
AI Cost Firewall is an OpenAI-compatible LLM gateway.
In a typical setup, the application sends requests to AI Cost Firewall instead of sending them directly to the LLM provider.
The flow looks like this:
Application
↓
AI Cost Firewall
↓
LLM provider
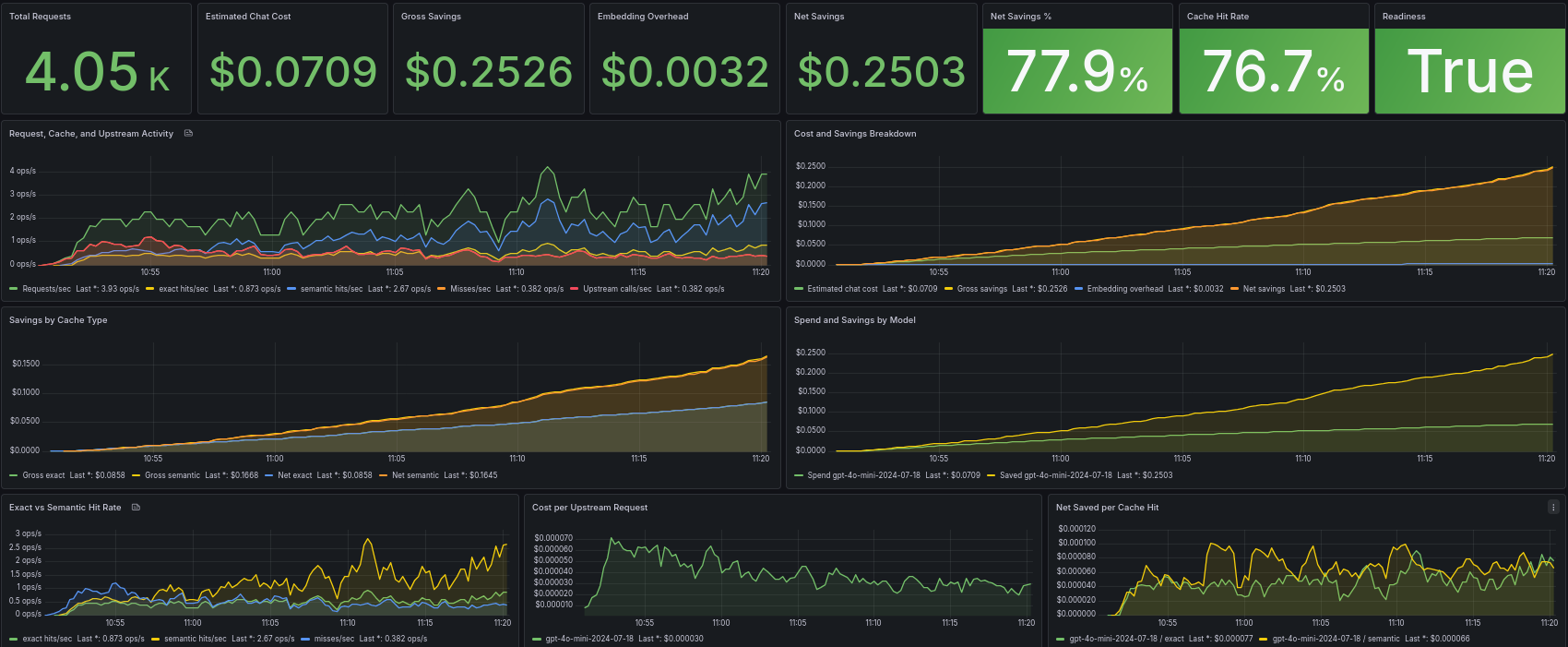
AI Cost Firewall can check whether a request is already known, whether an exact or semantically similar answer exists, and whether the upstream LLM call can be avoided.
For applications already using OpenAI-compatible APIs, the integration can be relatively simple. In many cases, the customer mainly changes the API base URL and API key configuration.
For example, instead of sending requests directly to an OpenAI-compatible provider, the application sends them to AI Cost Firewall first.
This makes AI Cost Firewall a good fit when the goal is to add a cost and cache control layer without deeply changing the application logic.
How VCAL Server is different
VCAL Server is a standalone semantic cache server. It is provider-agnostic. It does not depend on a specific LLM provider, chat API, or model vendor. Instead, VCAL Server works with vectors, cache entries, answer payloads, similarity search, and cache-management logic.
A typical VCAL Server flow looks like this:
User question
↓
Application creates an embedding
↓
Application searches VCAL Server
↓
If a good cached answer exists, VCAL Server returns it
↓
If not, application calls the LLM provider
↓
VCAL Server stores the new question and answer
This means VCAL Server can be used with OpenAI, Anthropic, Gemini, Mistral, Ollama, Azure OpenAI, OpenRouter, local models, or custom internal AI systems.
The important requirement is that the application must generate or provide embeddings that match the vector dimension configured in VCAL Server.
For example:
Embedding model: 768 dimensions
VCAL Server configuration: 768 dimensions
VCAL Server does not care which LLM provider generates the final answer. It only needs the vector representation and the cache payload that the application wants to store.
Integration difference
The biggest practical difference is how customers integrate the products.
AI Cost Firewall is designed for low-friction adoption in OpenAI-compatible applications. With AI Cost Firewall, the application can often continue using a familiar OpenAI-compatible request pattern. The firewall handles caching and cost-control logic in the gateway layer.
VCAL Server requires explicit application-level integration. With VCAL Server, the customer’s application needs to add cache lookup and storage logic. The application decides when to call VCAL Server, when to reuse a cached answer, when to call the LLM, and when to store a new answer.
Below is a simplified comparison:
| Area | AI Cost Firewall | VCAL Server |
|---|---|---|
| Main role | OpenAI-compatible gateway | Standalone semantic cache service |
| Integration style | Gateway / proxy-style | Direct application integration |
| Application changes | Usually minimal for OpenAI-compatible apps | Usually required |
| Provider dependency | Best suited for OpenAI-compatible APIs | Provider-agnostic |
| Cache control | Managed by the gateway | Controlled by the application |
| Best fit | Fast adoption and pilot deployments | Custom systems and deeper control |
| Purpose | Fast integration into existing OpenAI-compatible chatbots and AI applications | High-performance semantic cache for custom AI systems |
This distinction is important.
AI Cost Firewall is easier when the customer wants to add caching and cost visibility quickly.
VCAL Server is better when the customer wants more direct control over semantic search, cache behavior, thresholds, storage, and integration logic.
Is VCAL Server provider-agnostic?
Yes, VCAL Server is provider-agnostic because it works below the provider API level. It does not need to know whether the answer comes from OpenAI, Anthropic, Gemini, Mistral, Ollama, or a private model.
The customer's application is responsible for three things:
- Creating embeddings.
- Calling VCAL Server for cache lookup and storage.
- Calling the selected LLM provider when there is no suitable cached answer.
This makes VCAL Server useful in environments where teams use different LLM providers or want to avoid being tied to one API style.
Where AI Cost Firewall can be deployed
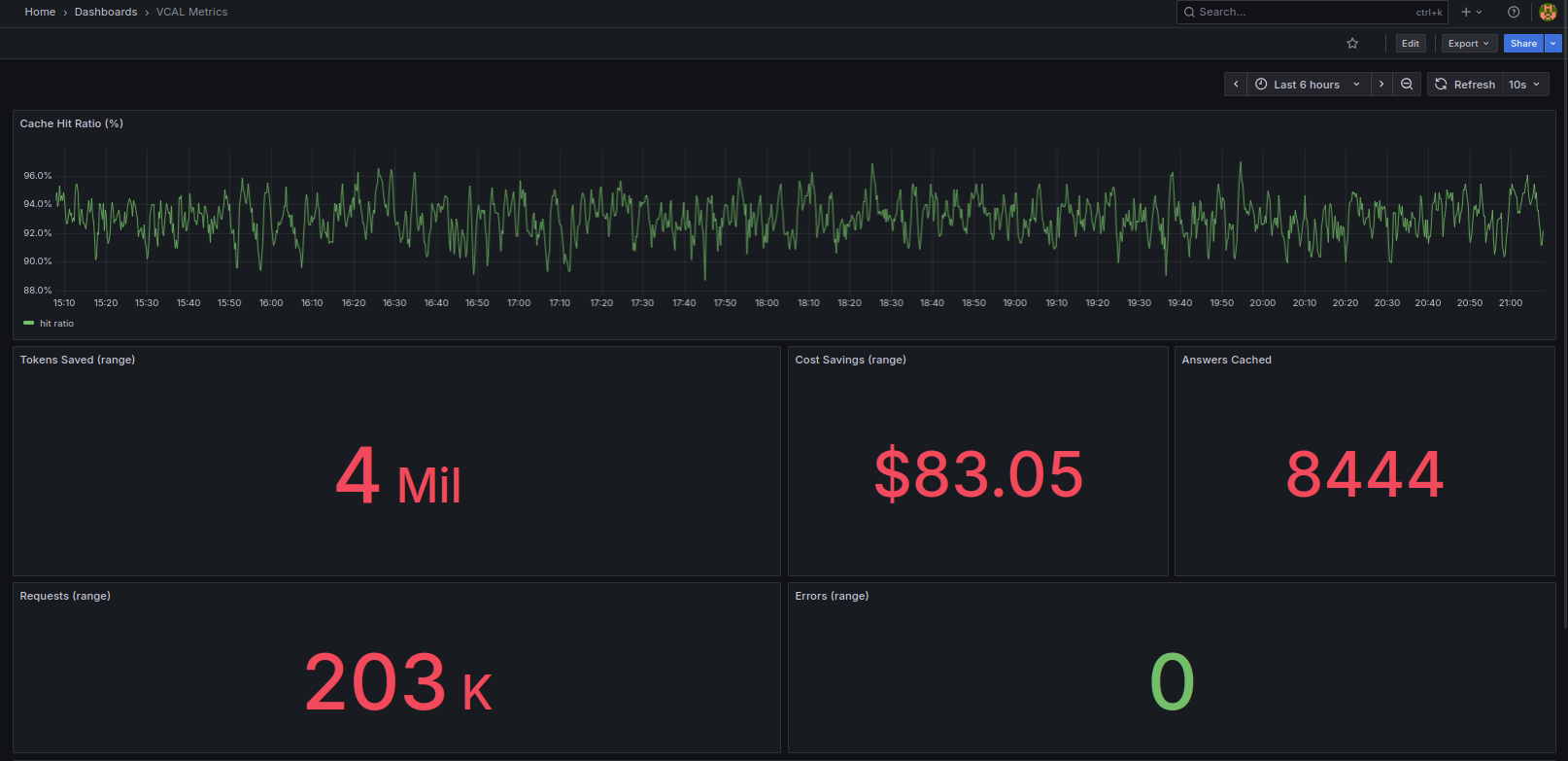
AI Cost Firewall is useful when the main goal is to reduce repeated LLM calls with minimal integration effort.
It is best suited for applications that already use OpenAI-compatible APIs and where teams want to add caching, cost visibility, and control without deeply changing the application code.
Common deployment areas include:
AI chatbots
Customer support bots, internal assistants, and FAQ systems often receive repeated or similar questions. AI Cost Firewall can reduce unnecessary upstream LLM calls and improve response speed.
OpenAI-compatible AI applications
Many applications already use OpenAI-compatible clients or gateways. AI Cost Firewall fits naturally into this pattern because it is designed around OpenAI-compatible API behavior.
Pilot AI deployments
Teams can evaluate LLM cost savings, caching behavior, and observability without rewriting the application. This makes AI Cost Firewall a practical starting point for controlled pilots.
In simple terms, AI Cost Firewall is best suited for situations where the customer wants a practical control layer in front of LLM traffic with minimal application changes.
Where VCAL Server can be deployed
VCAL Server is useful when the customer wants a dedicated semantic cache service with direct control over integration logic.
It works especially well in systems where the application team wants to decide how cache lookup, similarity thresholds, answer reuse, metadata, and storage should work.
Common deployment areas include:
RAG systems
Retrieval-augmented generation systems often receive repeated questions over the same knowledge base. VCAL Server can help reuse previous answers or decisions when the semantic meaning is close enough.
Enterprise knowledge assistants
Internal assistants for documentation, policies, procedures, and technical support can benefit from semantic caching because many users ask similar questions in different ways.
Agent workflows
AI agents often repeat planning, classification, summarization, or decision steps. VCAL Server can cache these intermediate or final results.
Custom chatbot backends
Teams building their own chatbot logic can use VCAL Server when they need more control than a gateway-only approach. The application decides how to use similarity scores, thresholds, metadata, and stored answers.
On-prem and private infrastructure
VCAL Server can run inside the customer’s own infrastructure. This is useful when data locality, internal control, and private deployment are important.
Provider-independent AI systems
Because VCAL Server is provider-agnostic, it can support applications using different LLM providers, OpenAI-compatible APIs, Anthropic, Gemini, Ollama, local models, or custom internal systems.
In simple terms, VCAL Server is best suited for situations where the customer wants a flexible and powerful semantic cache that the application controls directly.
When to choose AI Cost Firewall (a simple guide)
AI Cost Firewall is usually the better starting point when the customer wants a faster and simpler integration path.
It is especially useful when:
- the application already uses OpenAI-compatible APIs
- you want minimal code changes
- the main goal is to reduce repeated LLM calls
- the team wants cost visibility and cache metrics quickly
- the application architecture is suitable for a gateway layer
In simple terms, choose AI Cost Firewall when you want a practical gateway for reducing repeated LLM traffic with minimal or no application changes.
When you need VCAL Server
VCAL Server is usually the better choice when the customer wants more control and is ready to integrate caching directly into the application workflow.
It is especially useful when:
- the application uses multiple LLM providers
- you need provider-agnostic caching
- the team wants direct control over similarity thresholds and cache behavior
- the system is a custom RAG, agent, or chatbot backend
- you want a standalone semantic cache inside your own infrastructure
In simple terms, choose VCAL Server when you want a flexible and powerful semantic cache service that your application controls directly.
Compliance-conscious deployment
For many organizations, reducing LLM cost is only part of the problem. AI systems also need to fit internal security, privacy, governance, and regulatory requirements.
AI Cost Firewall and VCAL Server are designed to support compliance-conscious deployments.
They do not force teams to send their data through an uncontrolled external layer. Both products can be deployed inside the customer’s own infrastructure, where the organization can control network access, API keys, logs, metrics, retention policies, and operational monitoring.
This is especially important for teams working with customer support data, internal documentation, or sensitive operational information.
Can both products be used together?
Yes, in some architectures they can complement each other.
AI Cost Firewall can provide a gateway layer for OpenAI-compatible traffic, while VCAL Server can provide a deeper semantic cache service for custom workflows, RAG systems, or application-controlled cache operations.
However, they do not have to be used together. Each product has its own purpose:
- AI Cost Firewall is focused on easy gateway-style adoption
- VCAL Server is focused on flexible, provider-agnostic semantic cache infrastructure
Final thoughts
AI Cost Firewall and VCAL Server solve related problems, but they are not the same product.
AI Cost Firewall is an OpenAI-compatible gateway that helps applications reduce repeated LLM calls with minimal changes.
VCAL Server is a provider-agnostic semantic cache service that gives applications direct control over cache lookup, reuse, storage, and integration logic.
Both products are designed for real AI workloads where repeated or similar requests create unnecessary cost, latency, and infrastructure load. The right choice depends on the customer’s architecture.
If the goal is fast adoption with an OpenAI-compatible application, AI Cost Firewall is usually the better starting point.
If the goal is deeper control, provider independence, and custom integration, VCAL Server is the better fit.
I hope this guide helps you choose the right product for your AI application.
If you need more details, you can read the VCAL documentation or contact us directly.