What Actually Matters When You Try to Reduce LLM Costs
Originally published on Medium.com on April 5, 2026.
Read the Medium.com version
After publishing the first release of AI Cost Firewall, I thought the hard part was done.
The idea was simple and it worked immediately: avoid sending duplicate or semantically similar requests to the LLM, and you reduce cost.
I described that initial approach in more detail here: How to Reduce OpenAI API Costs with Semantic Caching
And it did work.
But once I started pushing it further — adding more metrics, handling edge cases, running real traffic through it — it became clear that the initial idea was only a small part of the problem.
Reducing LLM cost is not just about caching. It’s about understanding where the cost actually comes from, what “savings” really mean, and what begins to break when a system moves from a controlled demo into something closer to production.
The First Insight Still Holds
The original observation hasn’t changed, and neither has the core architecture. The system still solves the same underlying problem.
- Users repeat themselves.
- Applications repeat themselves.
- Agents repeat themselves.
Often the wording changes slightly, but the intent remains the same. From the model’s perspective, however, every variation is a brand new request. And every request has a cost.
So yes — caching works. It reduces cost immediately, often without any changes to the application itself.
But that’s only the surface. The deeper questions only appear once you try to rely on it.
The First Misconception: “Caching Is Free”
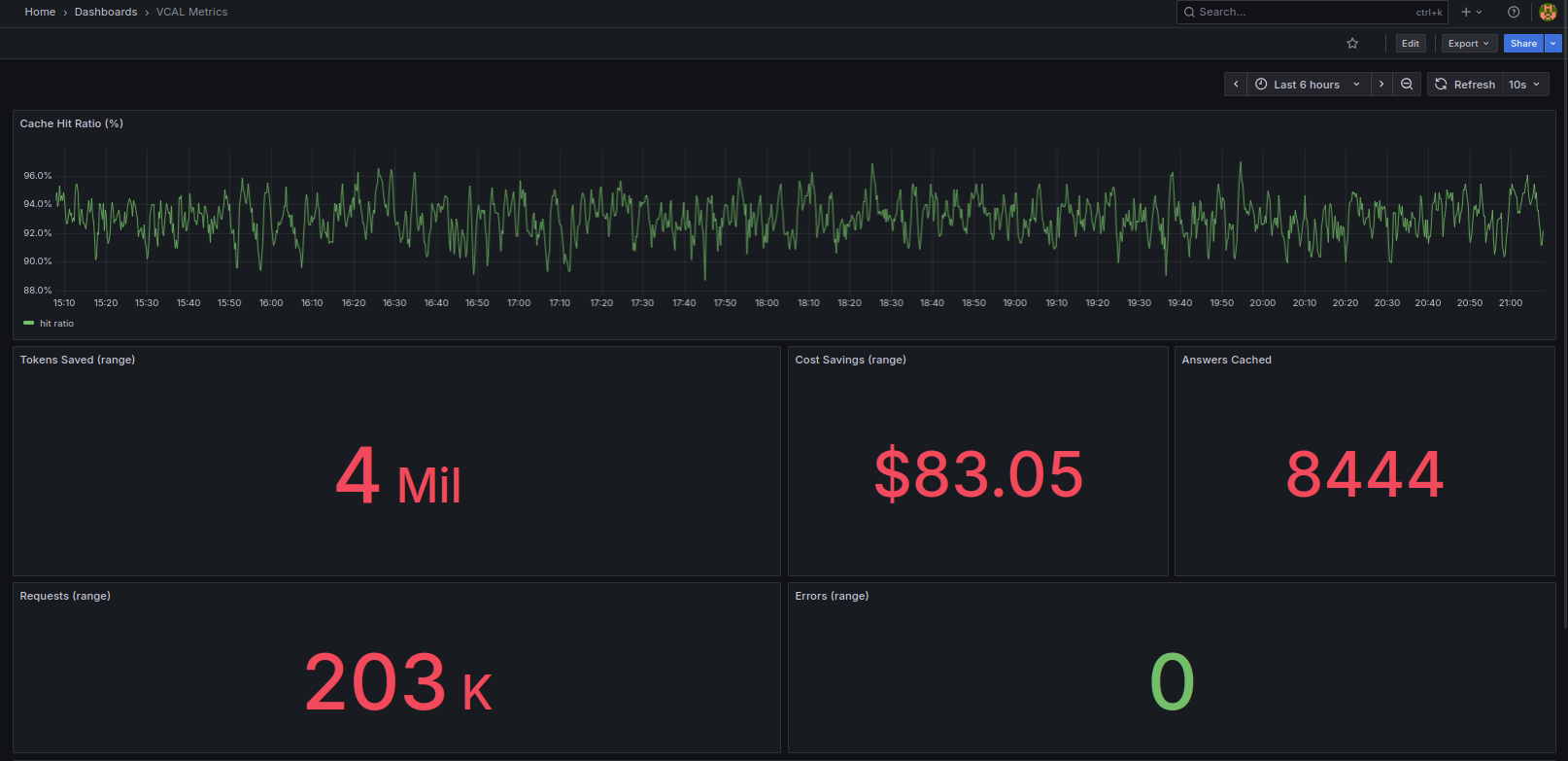
In the beginning, the results looked almost too good.
In a demo environment, exact cache hits dominated. When a request hit the cache, it meant no API call, no tokens, and almost zero latency. It felt like pure gain, as if cost reduction came with no trade-offs.
That illusion disappears the moment you introduce semantic caching properly. Because semantic caching requires embeddings.
To determine whether two requests are similar, you first need to convert them into vectors. That means calling an embedding model, storing the result, and comparing it against existing data. Only then can you decide whether to reuse a response or forward the request to the LLM.
And embeddings are not free.
At that point, the equation changes:
Net savings = avoided LLM cost − embedding cost
This is where things become more delicate.
If your similarity threshold is too low, you generate embeddings too often. If your traffic is highly unique, most of those embeddings never lead to a cache hit. If your embedding model is expensive, the optimization starts working against you.
What initially looked like a simple cost reduction mechanism becomes something that requires careful balance.
That was the moment when the project stopped being just a clever shortcut and started behaving like a system that needs tuning.