How to Reduce OpenAI API Costs with Semantic Caching
Originally published on Medium.com on March 21, 2026.
Read the Medium.com version
A simple OpenAI-compatible gateway that eliminates duplicate requests and cuts token usage
While working on LLM-powered tools for my customer, I kept seeing something that didn’t feel right.
Users were asking the same or similar questions again and again. Support queries repeated. Internal assistants received nearly identical prompts. Even AI agents were looping through similar requests.
At first, it didn’t look like a problem. That’s just how users behave.
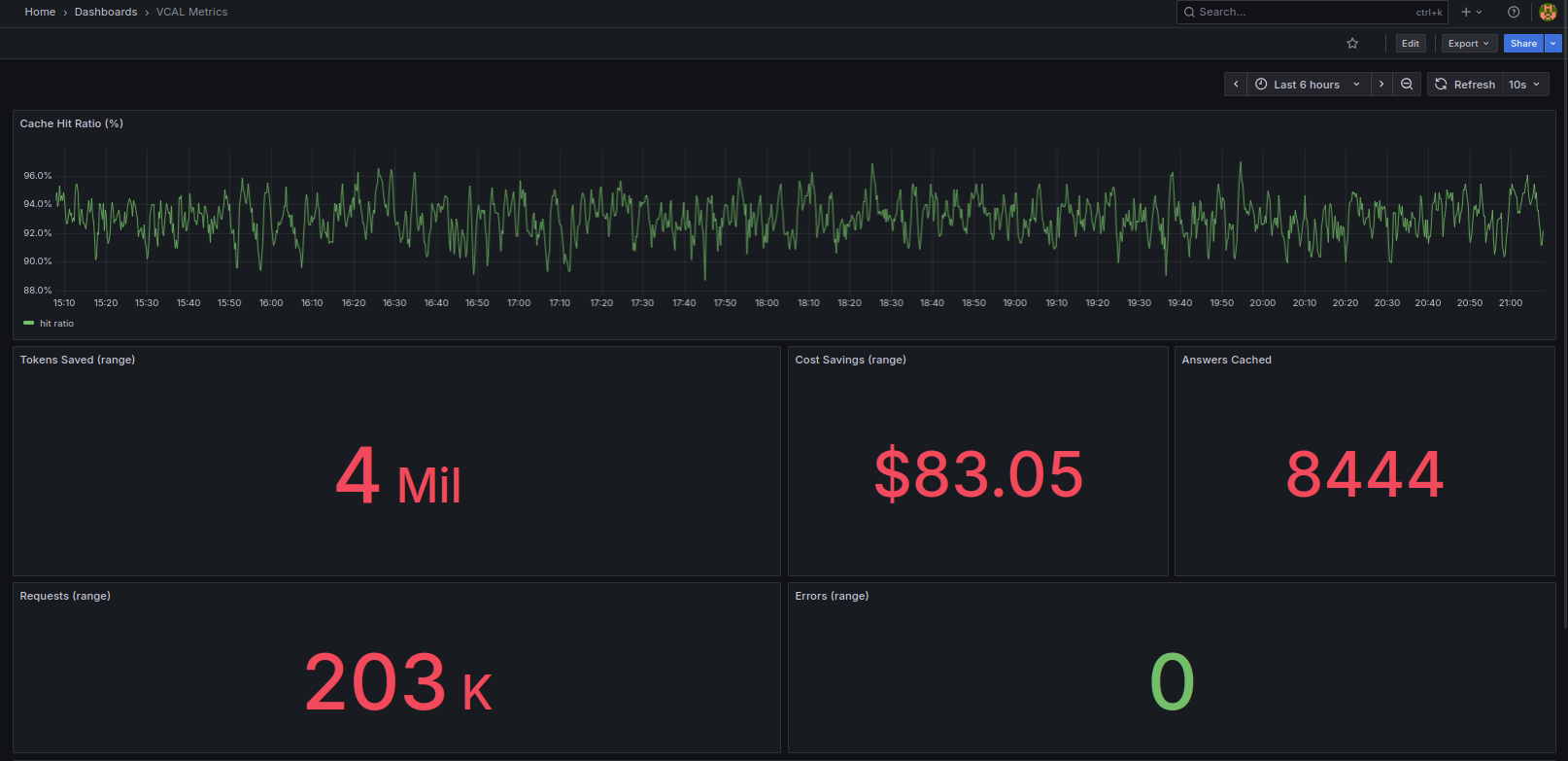
But then I looked at the cost.
Every repeated question meant another API call. Another batch of tokens. Another charge. Over time, it added up more than was expected.
I realized something simple:
We are paying multiple times for the same answer.
Why Existing Solutions Didn’t Quite Work
Initially I looked at the available tools.
Redis helped with exact caching, but only when the prompt was identical. The moment a user rephrased the question slightly, the cache missed. “How do I get access to Jira?” and “Cannot get access to Jira” were treated as completely different requests.
I also explored RedisVL, which brings vector search capabilities into Redis. It moves in the right direction by combining caching and similarity in one place. But in practice, it still requires setting up embedding flows, defining schemas, tuning similarity thresholds, and integrating it manually into the LLM request pipeline.
Vector databases like Milvus, Weaviate, or Qdrant seemed promising as well. They can detect semantic similarity effectively, but integrating them into the request flow means building additional pipelines, managing embeddings, and writing glue code.
All of these tools are powerful, but they aren’t simple.
More importantly, none of them are designed as a drop-in layer in front of an LLM API. There was no unified solution that combined caching, semantic matching, and cost awareness in one place.